QuickPeep: My work-in-progress small-scale web search engine
Frustration🔗
I have a few points of frustration with the common modern web search engines. For one, they tend to get gamed by content mill sites that specialise in Search Engine Optimisation (SEO). These very sites tend to be the ones that don't respect the reader, hammering them with nagging pop-ups, adverts, trackers and other distractions. I'm not even sure that many of these sites are actually written by a thoughtful human as opposed to being chucked together in a rush, or perhaps even by machine.
It's not that sites authored by individual people have gone away. If you know where to look (which is difficult), they still exist and I much prefer those. I suppose those people don't care about chasing all the latest SEO tricks and so they fall to the bottom of the results. That's understandable; it's enough effort to put a site together in the first place, why should they have to be bothered with the SEO games as well?
What I'm up to🔗
I thought to myself something along the lines of 'it's about time that someone makes a search engine which is specifically targeted at small websites and doesn't give you any rubbish'. Unfortunately, I then had to take personal responsibility for that statement and start such a project myself. :-)
I call it QuickPeep — 'quick' because it should be fast to get to desirable content and 'peep' because 'peep' means 'a quick look'. 'Peep' also describes one of the sounds made by some birds, so it's a perfect excuse to have a cute bird on the logo.
A few guiding principles of the project are:
Modest hardware requirements. The search engine should be operable with modest hardware requirements. Storage space is a particular concern. We obviously can't index the whole web, but even individual pages should be 'shrunk' down as much as possible so we can fit many pages into our search engine. Time is also quite limited: I simply don't have enough computers, or enough bandwidth, to trawl the entire web! I may be quite extreme about this goal. I won't turn my nose up at a 5% space improvement, for example — just because it's not an order of magnitude doesn't mean it's not worth doing (to me)!
No rubbish sites. Rubbish sites are not welcome. To minimise resource wastage, the best way to keep them out is to 'simply' not index them. This obviously comes with the implicit problem of somehow being able to know which websites are rubbish. Maybe someone clever could come up with a machine learning approach, but for now, I manually collect a set of sites that are allowed to be in the index. This is obviously quite 'human-intensive'.
Does what it's told. Some search engines will ignore your attempt to exclude terms, or they may disregard
"multiple word phrases"if they think they know better than you. QuickPeep doesn't do this. It should do what you say.Flexibility. This is quite difficult to provide when trying to cut down storage space, so it's a bit of a 'best-effort' point. QuickPeep should provide convenient features to help the reader in filtering out unwanted results. This may take the shape of being able to exclude terms within a query, or being able to exclude results for sites that don't respect them.
Open and free. It should be possible for more or less anyone to operate their own search engine based on this software. Ideally, they should be able to obtain some kind of data dump to avoid the hassle of crawling everything again if that's not what they want to do.
QuickPeep's pipeline and what it looks like to operate and use🔗
Seeding the search engine🔗
To start this project off, I assembled a collection of seeds — URLs that point to pages that I want in my search engine. Each seed implicitly vouches for (allows the crawling of) the same domain (or, in some cases, only some URL prefixes). I also came up with a handful of weeds — these are the opposite of seeds and correspond to URLs that we don't care about tracking, either because the site is too big to be practically indexable or the site doesn't belong in our focussed search engine.
Early on, I added a seed collection webpage to QuickPeep's web interface so that I could easily enter seeds (giving them tags) and even collect a few from friends and colleagues (thanks folks!). I only have about forty right now, but it's still enough to be interesting.
Raking the web🔗
Obviously, we need to get the content of interesting webpages into our search index so we can answer search queries. The first half of this — retrieving content from webpages — is what the QuickPeep 'raker' does.
The raker maintains its state as a libMDBX database and emits Zstd-compressed 'rake packs' which contain the page contents, references, site icons and errors.
The operator first imports a collection of seeds and weeds into the database using qp-seedrake. Each seed becomes an entry in the rake queue and also generates an entry in the set of allowed domains. Each weed creates an entry in the set of weed domains.
The operator can then start the raker itself (qp-raker). The raker splits off into separate tasks and will shut down when there is no more work to be done.
Each task selects a rakeable domain at random from the database and then processes queue items for that domain. A queue item is an instruction to download a URL, perhaps with an 'intent' for that URL (which determines what kind of document we're expecting). The raker is capable of understanding HTML webpages, RSS and Atom feeds and XML Sitemaps. Common image formats are also supported, but only if the raker is downloading a site's icon (becoming an image search engine is outside the scope of this project).
If we run into trouble whilst downloading from a domain, the raker can either generate a 'rejection' entry for that URL or, for temporary failures, we can back off from that domain until a later time.
For feeds, sitemaps and webpages, the raker extracts references to other URLs. These are emitted in the 'references' rake pack and:
- inserted into the queue (if the domain is allowed);
- inserted into the 'on-hold' queue (if the domain isn't one of the allowed domains); or
- discarded (for weeds).
For HTML webpages, the raker applies a few steps of pre-processing:
Advert (and other troublesome content) blocking and detection. The adblock engine from the Brave web browser is written in Rust and so was relatively easy to embed.
We use it for a couple of reasons: First of all, we can detect disrespectful (to a reader) 'nasties' such as adverts, trackers and 'annoyances' (including stupid cookie pop-ups1).
Second of all, we can trim extraneous bloat from the webpage content that we're aiming to index.1Cookie pop-ups are almost always a sign that the site is doing something disrespectful. They're not needed for legitimate use cases.
The vast majority of them are also infuriatingly difficult to dismiss without accepting; very few give easy rejection options.
In any case, they take your focus off the content (quite often covering a large portion of the screen) and so we will count them all as 'evil' for the pursuit of a pleasant experience. I'm relying on existing adblock rulesets here and definitely don't have the time to maintain one myself, anyway.Readability extraction. If you're aware of Firefox's Reader Mode, this is basically that. In fact, it's more or less exactly that — I use a (tweaked) Rust fork of Mozilla's readability.js project (thanks paperoni).
If you haven't heard of Reader Mode, then just know that it's a heuristic algorithm for extracting an article's main content from its web page.This could be a very useful technique for cutting down the size of the content that we need to index: we have no interest in being able to search for what's visible on the site's navigation menu, so why store it?
However, as this technique is more or less educated guesswork, I haven't entirely stripped away the content that isn't extracted as readable content, out of paranoia that some sites may not extract well. Instead, I'm considering ranking words in the 'readable' section more favourably than words elsewhere.
It's also possible to alter the ranking so that webpages with a relevant readable section are preferred over others, which could be nice for people that much prefer reading pages in Reader Mode.I still haven't decided exactly what I'm going to do with this; I'm not sure how I feel about being 'unfair' to webpages that don't fit in well with this non-standardised technique.
If it turns out that my concerns are unfounded, I may just strip out the non-readability-extracted content altogether and save some space!Conversion from HTML to a denser, less structured, format. Many of the bytes in a webpage are used to represent HTML tags that don't have any useful meaning for a search index.
For example, we don't care about the CSS on the page or most of the attributes on the tags. Similarly, tags like<div>often don't mean anything to us (especially not if they're nested); they're basically just there to make styling rules useful.This conversion pass reduces the structure of the page to text nodes, headings and links, plus some metadata (e.g. page title, page description and URL to the icon). (Headings could be useful to bias ranking. I haven't entirely decided about whether I should scrap links yet.)
This pass usually achieves a 80%+ reduction in document size and is a big part of making it cheap enough to store the content of so many web pages.Language detection. Many (maybe even most?) webpages don't seem to declare their language. On these, we sniff the language using Lingua. We don't actually discard non-English pages here (but we could...?).
Most likely, it might be useful to discard non-English pages when indexing, or to put them in a different language-specific index using the correct stemming rules for the language.
The document is then emitted into the 'pages' rake pack.
For icons, we decode the image, convert it to a lossy WebP with an unreasonably-low quality value (5%) and then emit it into the 'icons' pack. I'm sure I could afford to be more generous with the icons, but I've been impressed enough with the quality for the tiny size that I haven't bothered to.
The rake packs are compressed with Zstd (using a high compression level). Keeping the types of documents separated into different rake packs is good for two reasons; it improves the compression ratio as e.g. the pages rake pack contains mostly human-language text and doesn't have WebP icons randomly interspersed. The separation also means that you don't have to download all the rake packs if you don't need them; someone operating an indexer likely doesn't care about the references rake pack, but someone operating a raker may do if they want to rebuild their raker's state without reraking everything.
The raker can export Prometheus-compatible (or BARE Metrics-compatible, though I prefer Prometheus & Grafana for this situation) metrics. This gives you a way to see that it's making progress, as well as an idea of the sizes of various database tables (both in numbers of rows and in bytes/disk usage).
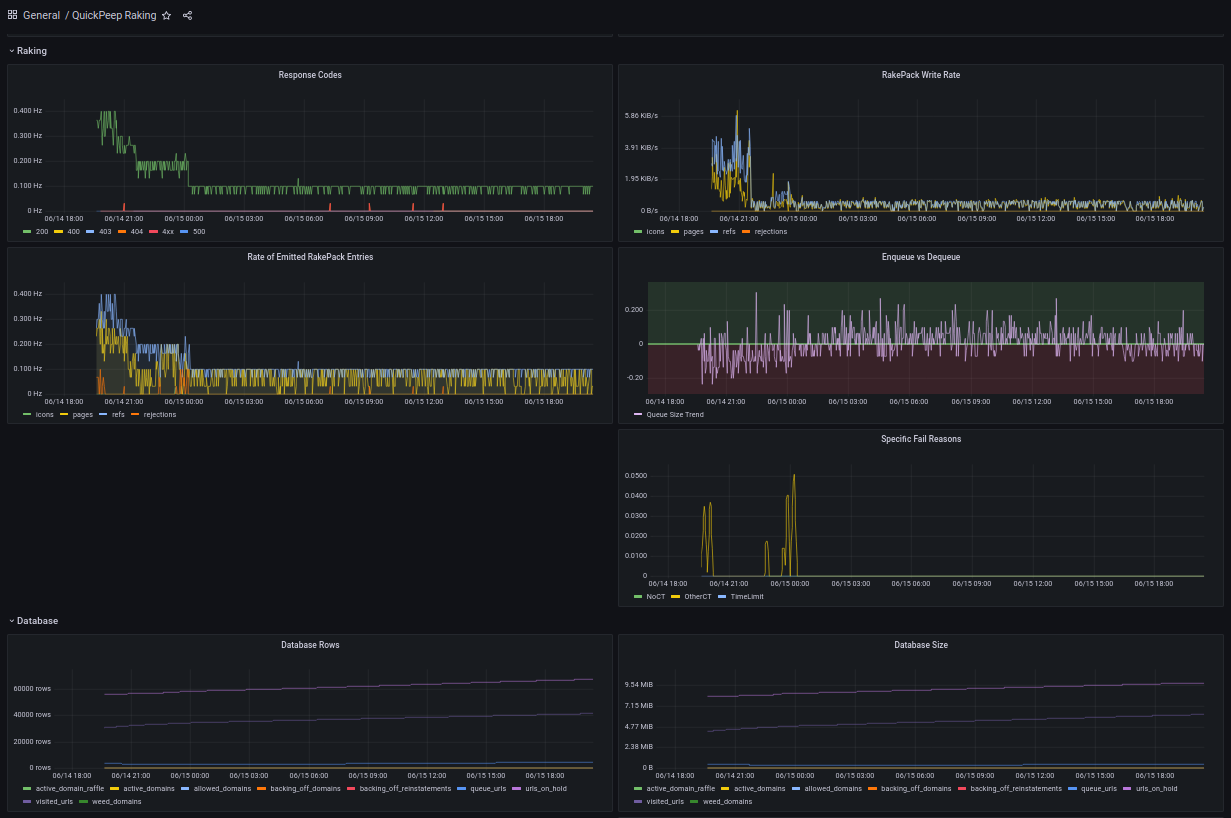 Figure: Part of a Grafana Dashboard for QuickPeep Raker. This is showing the slowest part of raking: the end, where only a couple of sites have not been finished.
Figure: Part of a Grafana Dashboard for QuickPeep Raker. This is showing the slowest part of raking: the end, where only a couple of sites have not been finished.
A quick aside about anti-features🔗
The raker identifies and tags pages with 'anti-features'2. These are aspects of a page or its site which may be undesirable for a potential reader.
For example, the presence of pop-ups (e.g. cookies, e-mail subscription nags, etc) or adverts may be reasons to avoid a site.
The raker also tries to identify sites that are sitting behind CloudFlare. This is because sites behind CloudFlare are often unbearable or even totally unusable for users of Tor; many sites impose at least a series of CAPTCHAs but some deny access to the content outright.
This can be extremely frustrating and seems to fit into the 'disrespectful to the reader' category.
Tor users should be able to use QuickPeep and exclude or down-rank these results if desired, to avoid wasting their time.
The inspiration for the term 'anti-features' comes from F-Droid, which applies this to Android applications.
Indexing web pages🔗
If someone wants to operate a search engine, they first need to set up an index.
QuickPeep is intended to support multiple index/search backends; currently Tantivy (an embedded search engine) is implemented but I'm interested in trying MeiliSearch (a search engine server) to see how it compares.
The operator configures their index of choice (Tantivy is easy as there's no need to set up a separate server).
The operator can then download and import the rake packs, either from their own raker or from a public repository of rake packs (e.g. mine! — once things are a bit more stable).
The operator uses qp-indexer to index the entries from the rake pack (this also imports icons into a small key-value store so that the web interface can find them).
There is a command-line tool, qp-index-search, to search the index, which can show that things are working.
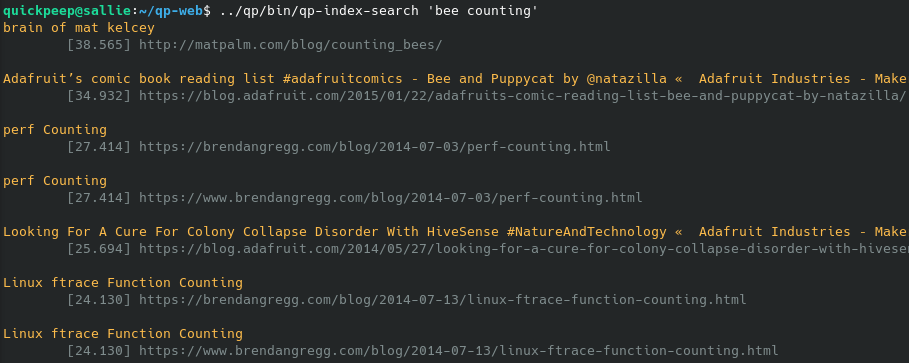 Figure: A search for 'bee counting' using
Figure: A search for 'bee counting' using qp-index-search. This tool is also interesting because it shows the relevance score of each result.
Searching the index🔗
The quickpeep binary serves a web frontend to the index, offering a simple text box and button-based interface for performing searches.
The layout is quite minimal, which I like here (but it currently looks rubbish on light mode, I'm afraid. If your browser doesn't advertise a preference for dark mode, be warned :-)).
Right now, I just pass my query in to Tantivy fairly directly and don't try anything too intelligent or sophisticated to refine the results. Luckily, Tantivy also supports common search operators (such as +word, -word, "multiple word phrase", etc), so we get these 'for free'. I also take Tantivy's excerpts/snippets directly.
There is no PageRank algorithm or anything, it's all just plain full-text search ranking.
A quick play with the search engine reveals that it doesn't feel like it's giving me as much 'relevance' as other search engines do. I imagine some refinement could go a long way to improving this.
That said, I've also compared a few queries to DuckDuckGo and some of them aren't really any different. Naturally, only having about forty sites in the index rather than ...millions(?) is bound to mean that some queries struggle to find much relevance, though.
I've also found some interesting articles through QuickPeep and I've enjoyed reading them, so it's not that much of a flop!
Once I can think of how I can improve this, I'll give it a go. Trying MeiliSearch may be interesting as a point of comparison and I may get some ideas along the way.
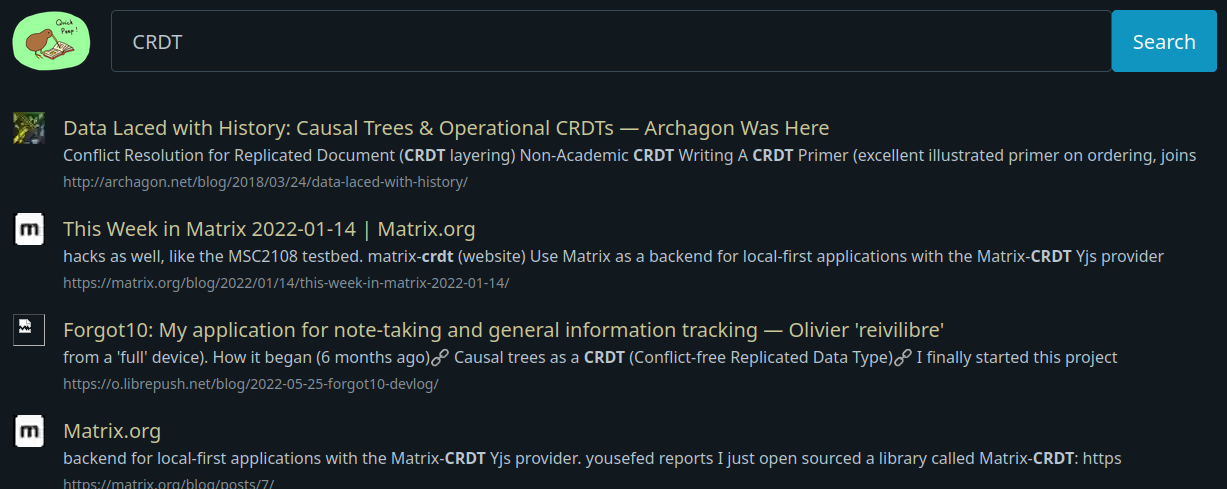 Figure: A search for 'CRDT' in QuickPeep's web frontend
Figure: A search for 'CRDT' in QuickPeep's web frontend
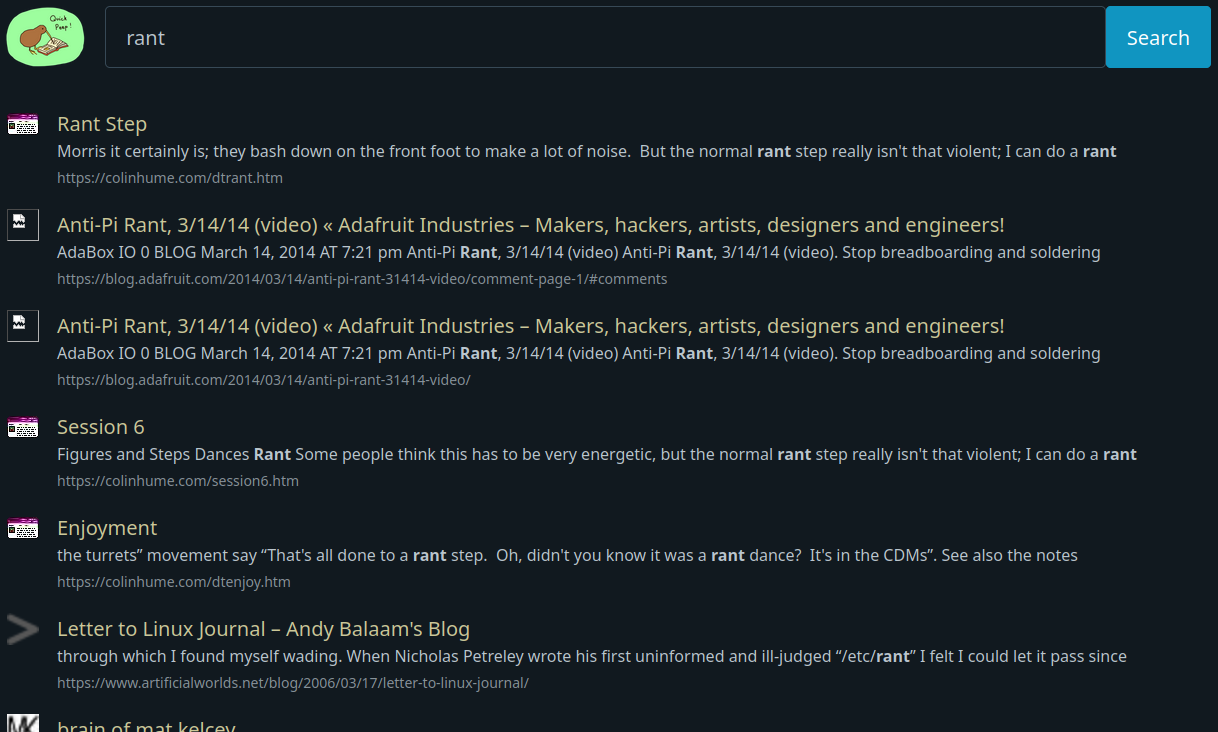 Figure: A search for 'rant' in QuickPeep's web frontend
Figure: A search for 'rant' in QuickPeep's web frontend
Brief comment on disk usage🔗
Ideally I should try and get at least thousands of sites into the index before thinking too much about this, but again, disk usage is an obvious concern when operating a search index. How much space am I using for these ~forty sites?
- Search Index
- Tantivy index: 150 MiB (I don't know how this will scale and how much of this is overhead that is exaggerated on a small database.)
- Icons store: 76 kiB (Much of this will be overhead since the database is so small and it uses 4 kiB pages.)
Icons themselves are typically about 200 bytes.
- Rake packs: 28 MiB (note that these can be deleted after they've been indexed; they're just a data transfer format. But it'd be useful to be able to host them for others to operate their own search engines.)
- Raker database: 17 MiB (Much of this is 'on-hold' URLs. This could be reduced by marking some of them as weeds if we're not interested in indexing them.)
The size of the Tantivy index seems to be the most worrying, especially since you can't really delete it if you still want to search for things!
It may be worth adding Zstd support to Tantivy's document store (currently it uses LZ4, which is fast but has a much lower compression ratio) and using it to compress entries. Training and using a Zstd dictionary should give us a good compression ratio. Decompression will be slower, of course, but it's still likely good enough.
Alternatively, I believe it's possible to not store document text itself in Tantivy's datastore.
The biggest files in Tantivy's index seem to be .pos and .idx files, so I'm not sure improvements in the document store are going to buy much anyway. I note that zstd can cut one of the .idx files down by 50% and one of the .pos files down by 20%. Perhaps it's worth using a compressed filesystem?
I presume the large .pos files are indices of the positions of all the terms in the document (primarily useful for "multiple word phrase" search terms, as far as I know).
I suppose those could be turned off altogether at the cost of making "multiple word phrase" queries slower (as they'd have to find the positions in the document itself).
According to Paul Masurel's blog post about Tantivy's indexing (which I just submitted as a QuickPeep seed :^)), it should be possible to make the index itself smaller than the document, if term positions are disabled.
Barely usable🔗
...but open! QuickPeep is open-source: quickpeep. My collection of seeds and weeds is open data: quickpeep_seeds.
If you'd like to give it a try, you can visit https://quickpeep.net, but don't get your hopes up :-)!
Known problems🔗
- Quality of excerpts is usually poor.
- Ranking can be a bit poor.
- Pages without favicons show an ugly broken image.
- Duplicate webpages show up as duplicate results — QuickPeep should try and canonicalise URLs a bit and look for similar pages.
- It's probably quite easy to deal with the most common culprits: canonicalise a URL (for deduplication purposes only) by removing trailing
/, ignoring the protocol scheme (https://) and ignoring awww.subdomain if present. - I have some vague plans to use SimHash to try and tackle the duplicate page problem more generally.
- It's probably quite easy to deal with the most common culprits: canonicalise a URL (for deduplication purposes only) by removing trailing
- Dynamic 'category' or 'home' pages should be favoured less than the pages that they contain excerpts for.
- Some simple heuristics will probably help a lot here, e.g. favouring the longer URL.
- Antifeatures are not used at all. They're not even displayed.
- The size of the Tantivy index is slightly worrying, but there are ways to improve it.
- Try and add in Zstd support; use Zstd with a dictionary?
- URL fragments (
#blah) should be stripped when raking.
Aside: other uses for the 'references' rake packs🔗
When a lot of sites have been crawled, it'd be fun to load the 'references' rake packs into some kind of graph database and be able to answer queries like 'which pages refer to my page'.
Reverse references like this could be quite interesting for finding extensions or different points of view to an article you are already aware of.
(This would be gamed for SEO purposes in a heartbeat on a conventional search engine!)
Because these rake packs will be available for download, it should be quite possible for someone to do this if they like.
Thanks🔗
QuickPeep is built on top of many great quality, open-source libraries.
Many thanks to all their authors for putting their work out into the open for fools like me to enjoy!