Forgot10: My application for note-taking and general information tracking
I've been working on a 'note-taking' system for a few months now. I think I have some interesting ideas and I thought it'd be worth a blog post so that I can look back and remember what I did these past few months...
Motivation and rough idea🔗
I'd like to do a better job of making notes of things and being able to retrieve information that I've come across. All too often, I've been stuck trying to remember something that I know I've done before, or that I know I've seen somewhere (probably on the Internet). It'd be useful to me to have a system that lets me take notes in a natural way and then lets me search those notes and anything else that might be useful.
I currently use Zim for my notes. It's a cracking tool that calls itself a 'Desktop Wiki'. The pages themselves are stored in a textual format. With that said, it has a few limitations and I have a few itches for extra functionality which tempted me to roll my own tool...
Peer-to-peer sync🔗
I use Syncthing to synchronise my Zim notebooks. It's peer-to-peer and files synchronise directly between my computers (and 'smart' 'phone'). I really like it, but I have occasionally ran into sync conflicts when I modify my Zim notebooks on two different machines concurrently (e.g. because often only one of them is on at once). Sharing a Zim notebook with a friend can also lead you to the same problem if you try to concurrently update the same page.
As a result, a wish for my tool is to not only allow near-flawless offline use (since I'm often offline), but also to synchronise my different computers when they have the opportunity. To this end, I want to use Conflict-free Replicated Data Types (CRDTs).
Streams, Pages and inline actions🔗
My tool should be able to adapt to at least two frames of mind: sometimes, there's a need to quickly get a note down or 'stream' thoughts from mind to page. In this situation, the tool should ideally get out of the way and pose as little interruption as possible to getting those thoughts on the page!
At other times, collecting nicely-polished notes together is desirable and I wouldn't mind putting some time into organisation. In this situation, the tool should give options to 'cultivate' a structured repository of information.
For the first case, I came up with the concept of a 'Stream' (although if it seems sensible, it would be possible to have multiple of them). A Stream is just a chronologically-ordered list of entries (small rich text documents). It's intended for off-the-cuff journalling. The application should let you enter commands as you write an entry, so that e.g. you can easily schedule a reminder for yourself, without needing to even take your hands off the keyboard or leave the Stream at all.
So far, I have /reminder (aliased as /r) which lets you schedule a reminder, potentially recurring, using plain English 'syntax'. See:
Video demonstrating its use:
When you're not making rapid-fire notes, the tool should let you write to a hierarchical tree of note Pages. These can be navigated to like Zim's pages. They have a (required!) slot for a page title and they are intended for me to come back to time and time again.
Screenshot of a Page: 
Search... everything!🔗
A tool like this would benefit from good search to be useful. It's tempting to take this one step further and pull in extra sources of information to be indexed.
For example, it may well be interesting to dig up browser history and archive the contents of the pages that I've been reading. It might be useful to archive e-mails and Matrix messages and index those, too.
I haven't gotten anywhere with this yet, but it's a wish for the future.
Multiple libraries🔗
I want to support multiple 'repositories of information'; I decided to call them 'libraries'.
Rather than being completely separate notebooks, though, they should all be merged into one unified view when desired. The tool should let you enable/disable them at will.
A crucial point is that it should be possible to support different devices having different libraries (e.g. my work machine may only have relevant notes on there) and they should be able to go 'missing' without causing any harm (so that you can use an encrypted filesystem to store private notes and only unlock it when you need access).
I note that it may be interesting to support a device having a partial/limited portion of a library, especially once it's possible to embed media like photos/videos, so that e.g. a PinePhone with limited storage can be used to some extent, even if it means not having access to bulky media (or having to pull it over the network from a 'full' device).
How it began (6 months ago)🔗
Causal trees as a CRDT (Conflict-free Replicated Data Type)🔗
I finally started this project after reading Data Laced with History: Causal Trees & Operational CRDTs by Archagon (blog post). I had been keeping an eye on CRDTs for a while and saw this blog post as a way to finally get my hands dirty — by implementing one! It's a little bit lengthy and requires a bit of focus to get through, but I do highly recommend it. (This section may not make much sense if you (understandably) don't read the blog post, so skip if desired.)
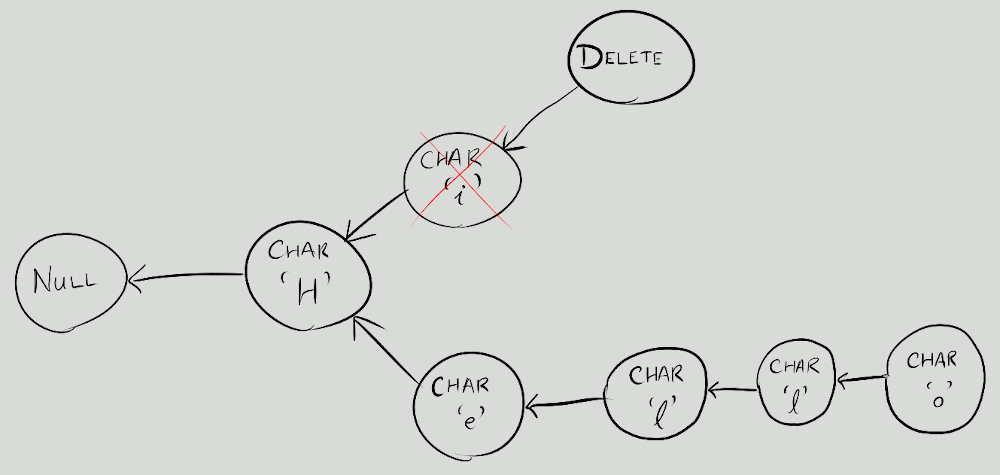
I learnt a lot by actually writing some code; some of the trickier parts in the blog post started to click into place. Once I had something basic that looked plausible, I took a bit of time to make it generic so that the causal tree logic itself was able to accept any 'atom' type (and they could have their own rules about priority, so that it was possible to support the special ordering rules for atoms like 'Delete' and some others that would be useful for a rich text schema later on). It was highly satisfying to have the basics working (insert, delete and the merge of two documents), even just in plain text at a command-line prompt. Illustration of plain-text causal tree atoms and how they fit together: Extending this to rich text required a bit of thought. I decided to have 'descriptors' for marks and embeds; these descriptors precede the content of the document and only store attributes (e.g. the target of a link). This allows you to move the embeds or start and end of a mark, without having to copy all the attributes and duplicate the data. The priority rules are extended so that the descriptors come before the content of the document and so that Illustration of rich text causal tree atoms and how they fit together: Thoughts about supporting undo/redo made me also allow cancelling a deletion by deleting the Too much detail about causal trees and the types of atoms I used. (Click to expand)
pub enum PlainTextCausalTreeValue {
/// The root of the document.
Null,
/// A text character; 1 unit wide. Comes after the atom that it points to.
Character(char),
/// Delete the unit to which this atom points.
Delete,
}
EmbedHere, MarkStart and MarkEnd are added as extra kinds of atoms that can be used within the content of the document, along with Character (and Delete!). They have an additional reference to their descriptor.Attributes cling tightly to their parent descriptors (but no tighter than the Deletes). This allows you to read the document's atoms sequentially and populate a map of all the descriptors and their attributes easily.pub enum RichTextCausalTreeValue {
/// The root of the document.
Null,
/// A text character; 1 unit wide. Comes after the atom that it points to.
Character(char),
/// An anchor positioning an embed, with reference to an embed descriptor.
/// Embeds are 1 unit wide. Comes after the atom that it points to.
EmbedHere(StorageAtomLocator),
/// Delete the unit to which this atom points.
Delete,
/// Start a mark.
/// 1 unit wide. Comes after the atom that it points to.
MarkStart(StorageAtomLocator),
/// End a mark.
/// 1 unit wide. Comes after the atom that it points to.
MarkEnd(StorageAtomLocator),
/// Out-of-band descriptor for a Mark. Points to Null.
MarkDescriptor(MarkType),
/// Out-of-band descriptor for an Embed. Points to Null.
EmbedDescriptor(EmbedType),
/// An attribute on a Mark or an Embed. Points to a MarkDescriptor or EmbedDescriptor.
Attribute(Attribute, AttributeValue),
}
#[derive(Copy, Clone, Debug, PartialOrd, PartialEq, Ord, Eq)]
pub enum RichTextPriority {
NormalText,
NormalMark,
HugAsChildValue,
HugToDeleteParent,
}
impl AtomBody for RichTextCausalTreeValue {
type Priority = RichTextPriority;
fn priority(&self) -> Self::Priority {
match self {
RichTextCausalTreeValue::Null => RichTextPriority::NormalText,
RichTextCausalTreeValue::Character(_) => RichTextPriority::NormalText,
RichTextCausalTreeValue::EmbedHere(_) => RichTextPriority::NormalText,
RichTextCausalTreeValue::Delete => RichTextPriority::HugToDeleteParent,
RichTextCausalTreeValue::MarkStart(_) => RichTextPriority::NormalText,
RichTextCausalTreeValue::MarkEnd(_) => RichTextPriority::NormalText,
RichTextCausalTreeValue::MarkDescriptor(_) => RichTextPriority::NormalMark,
RichTextCausalTreeValue::EmbedDescriptor(_) => RichTextPriority::NormalMark,
RichTextCausalTreeValue::Attribute(_, _) => RichTextPriority::HugAsChildValue,
}
}
}
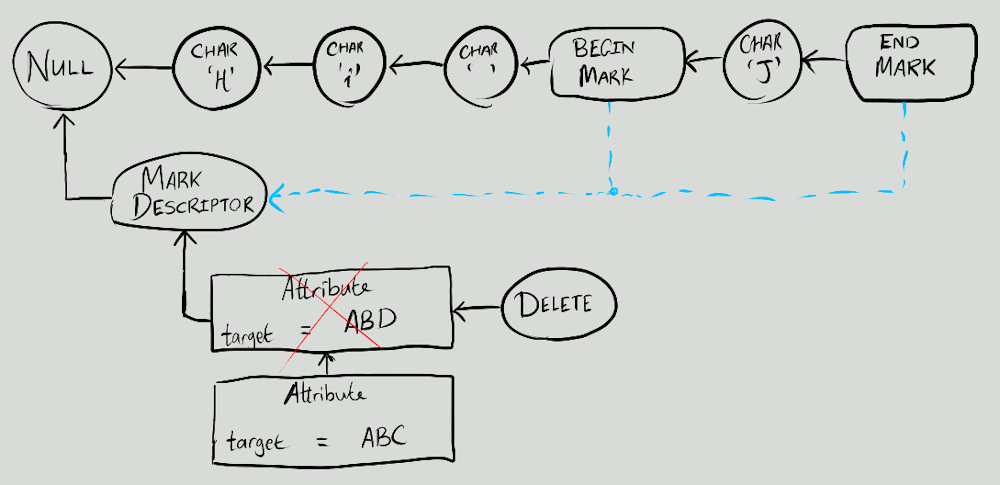
Delete atom. (In this case, to undo some operation, you just need to track which atoms are created for that operation and create Delete atoms for them. Redo is the same as undoing the undo!) Because Delete clings the tightest to its cause/parent atom, you can easily check whether a particular atom is 'not deleted', 'deleted', 'deleted but the delete was deleted' and so on — merely by more or less scanning ahead and counting the number of Deletes that follow (with the main exception that you need to be careful not to double-count concurrent Deletes: two people deleting the same thing doesn't mean it should come back!). I'm not sure whether the idea of being able to un-delete is overall sensible or not (I haven't used this enough in practice), but I thought it was interesting nonetheless.
Rolling my own rich text editor🔗
I was keen on using the egui GUI library. I had used it for a couple of projects and it felt pleasant to write code with it.
This lead to weeks of rolling my own rich text editor in egui (using the causal trees as a backing representation). It was a fun exercise and I got a half-decent starting point working! That said, it was quite tricky to come up with a simple enough plan to efficiently update the rendering state for incremental changes.
I got something decent working for a line-based editor — you can just follow the causes of atoms until you find the start of the line and then reflow only one or two lines at a time! On the other hand, I really struggled to come up with an efficient method to lay out and render rich, nested structures (with incremental updates) without shedloads of effort or fiddly code and I had quite a few dead ends.
Eventually, I realised that, if I wasn't careful, this would be an uphill battle for the entire project, especially as this is for a media-rich application and that just maybe it wasn't the best idea to write my own layout engine when you get one for free in a modern web browser. I also knew that supporting photos and videos would likely involve quite a bit of fiddly code to interface with decoders and manage GPU textures, whereas modern HTML is able to handle media with relative ease.
In short: egui is great, but HTML and a web browser engine really wins for this use case, at least if roll-it-yourself complexity is on the list of concerns.
A new plan (3 months ago)🔗
Realising how much I'd gotten myself into and wishing for faster progress, I made the decision to abandon the hopes and dreams of a native application and switch over to doing something in the browser.
I learnt how to use Vue.js and how to embed my web application into a webview using Tauri (like Electron, but lighter weight) so that it could eventually become 'close enough' to a plain desktop application. I learnt how to write TypeScript because I thought it'd be sensible to have a little bit more rigidity and safety than JavaScript typically imposes.
On the frontend, I picked up the Tiptap rich text editor and used its built-in support for the Yjs CRDT. The frontend connects to a daemon over a web socket in order to load and store data; in the future, it may be possible to use Tauri's messaging interface, but I wanted to leave the doors open to using Forgot10 outside of Tauri as well in order to support some future ideas.
The Forgot10 daemon is responsible for notifying any connected clients (frontends) about document updates, storing data in SQLite databases and synchronising with other peers. Other peers are discovered using mDNS (by publishing and listening for advertisements with Avahi). Peers are identified by the hash of their TLS certificate, which they also advertise in their mDNS advertisement (so they can be identified before trying to connect). All changes to documents are pushed through an event bus (which allows listeners, such as syncing peers and connected clients, to receive updates in real time) and into a buffer that will occasionally flush them to disk. (The disk flushing operation just stores new fragments of the document and will occasionally coalesce them together if there are too many.)
All of the documents' metadata are stored in the Yjs documents themselves, but a separate 'derivation' pass extracts or derives metadata (such as the title of a Page, or the timestamp of a Stream entry) from the Yjs document and caches this in the SQLite database. Caching the metadata in the SQLite database is crucial as it prevents us from needing to load all the Yjs documents in order to display a list of pages or in order to sort Stream entries chronologically. The derivation pass is also the time at which special nodes like reminders can be tracked in the database so we actually get notified in the future, or (one day) when the search index could be updated with the document's content.
As the Rust port of Yjs is not ready enough yet, I resorted to running a Node.js process to load documents into Yjs on the daemon and perform various operations on them. (I tried several embeddable JavaScript interpreters but alas, this was the best solution I could get to work for now. At least it doesn't segfault :)) Once the Rust port of Yjs is ready, I'm looking forward to ripping this out.
Rough architecture of Forgot10 at the moment: 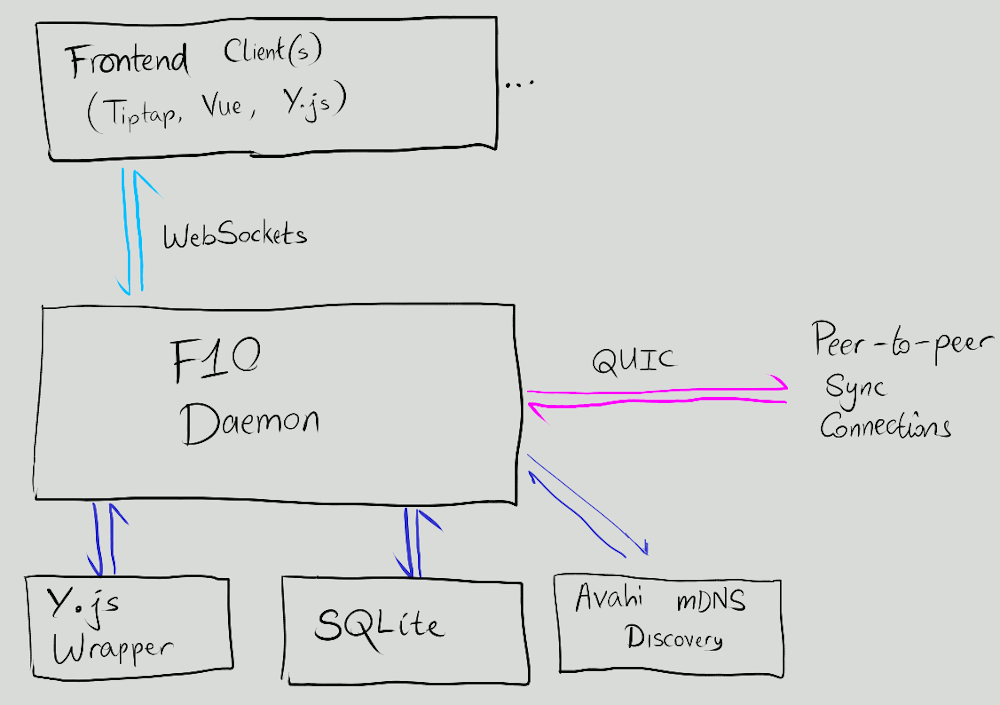
It's a start...🔗
What I have at the moment is a multi-document rich-text editor, that works entirely offline but then will also work as a peer-to-peer collaborative editor, with impressively-live updates.
Seeing it work for the first time and then having the chance to use it with someone else was very satisfying. Yet, frankly, most of what I've written so far has just been glue! It just goes to show what high-quality libraries are around these days and the cool things you can do by gluing them together.
The cherries on top for my project have yet to come, but the foundation is there. What I'll be taking a look at doing soon is:
- Using it in practice and trying to get a feel for what's nice and what's awkward to use.
- A LOT of cleaning up...
- The document store could be a little more self-contained and have an easier interface to use. It's tempting to pull it out into a library that can be reused for other projects, if that could work without making it too difficult to track the extras.
- The GUI frontend needs some love. There are a few bugs I'm aware of that I've left until now, in trying to focus on getting something working.
- Implementing reminders properly: pull them out of the document during derivation; show an overview of upcoming reminders; and actually notify when it's time.
- Search.
- Media (photographs etc).
- Export to HTML, to PDF and to Markdown. (I have experience with this from a prior project where I used ProseMirror, the library Tiptap is based on, and exported to HTML & PDF when necessary.)
- Improvements to the build scripts and packaging so that it's easy to build and install. (There are a few manual steps at the moment, which arguably Cargo should be doing for you.)
There's a lot to sort out before I'll feel comfortable opening it up for others to use (or even to read the code). That said, this is a serious project that I intend to keep around for the long term (it's not just an experiment or a proof of concept), so given time, I will get there.